




« Espoir? | Page d'accueil | Stanley Kubrick for LOOK Magazine »
10/08/2008
Let’s talk about stats.
Je vais essayer de faire une petite synthèse sur le théorème de Bayes, sans rentrer dans une théorie qui m’est largement imperméable, c'est à dire en restant pratique.
D’abord, les présentations.
Je vais m’intéresser exclusivement à l’étude de la performance d’un test médical de dépistage T d’une maladie M.
T peut être positif (T+), ou négatif (T-)
Un sujet peut être atteint par la maladie (M+) ou sain (M-)
|
| M(+) | M(-) |
| T(+) | VP | FP |
| T(-) | FN | VN |
VP= vrai positif, FP= faux positif, VN= vrai négatif, FN= faux négatif
La sensibilité Se est la capacité d’un test à identifier correctement les sujets malades.
Se= VP/ (VP+FN)
La spécificité Sp est la capacité d’un test à identifier correctement les sujets sains.
Sp= VN/ (VN+FP)
Note : pour déterminer qui est malade et qui ne l’est pas, il a fallu utiliser une méthode indiscutable (on verra que c’est justement un point discutable en pratique) et indépendante du test T. On peut alors disposer de deux populations « indiscutables » : les sujets sains et les sujets malades.
Ca va pour l’instant ?
Allez respirez un grand coup, ça se complique un peu.
Malheureusement, du moins pour la simplicité, la vie n’est pas blanche ou noire, il y a beaucoup de gris.
C’est pareil pour les tests médicaux.
L’ensemble des individus d’une population donnée n’aura pas un même résultat du fait de la variabilité biologique.
Ces résultats vont se distribuer selon la loi normale de Laplace-Gauss, et donner une belle courbe de Gauss (qui aurait pu s’appeler courbe de Laplace, sans ce maudit allemand !).
Quand on compare deux populations, les malades M(+) et les sains M(-), il y a de grandes chances que les deux courbes se croisent.
C'est-à-dire qu’il va falloir déterminer un seuil qui permettra de déterminer des sujets T(-) ou T(+).

C’est là que ça se complique, car déterminer ce seuil (en rouge sur les courbes) est une délicate question d’équilibre entre la sensibilité et la spécificité. Il va falloir choisir de privilégier l’une ou l’autre.
Plus le seuil est bas, plus on va diminuer le nombre de FN (on va donc augmenter la sensibilité), mais on va aussi augmenter le nombre de FP, et donc diminuer la spécificité.
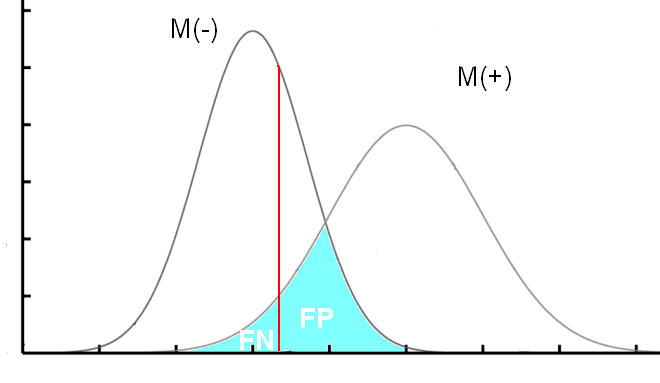
Je ne vais pas rentrer dans les détails, mais ce choix dépend de ce que l’on veut faire du test, c'est-à-dire si on veut le rendre très spécifique ou au contraire très sensible. On peut aussi déterminer ce seuil à l’aide d’une courbe « ROC » (Receiver Operating Charactéristics).
Mais sachez que le choix d’un seuil de positivité d’un test est délicat, complexe et parfois sujet à caution.
Dans la vie réelle, le patient et son médecin se fichent un peu de savoir quelle est la sensibilité, la spécificité d’un test, ou si sa courbe ROC est sexy.
Ce qu’ils veulent savoir c’est
Quelle est la probabilité d’être malade quand le test est positif, c’est à dire la valeur prédictive positive (VPP)?
Quelle est la probabilité d’être sain quand le test est négatif, c’est à dire la valeur prédictive négative (VPN)?
C’est là qu’intervient le théorème de Bayes (qui aurait pu s’appeler théorème de Laplace, sans ce maudit anglais !).
Pr est la prévalence de la maladie dans la population, c'est-à-dire la proportion de la maladie dans une population définie, à un instant t
Pr = nombre de cas observés à un instant t /population à risque au même instant t
VPP = (Se*Pr) / (Se*Pr)+(1-Sp)*(1-Pr)
VPN = (Sp*(1-Pr)) / (Sp*(1-Pr) + (1-Se)*Pr)
Deux « grosses » formules que seuls les étudiants en médecines qui doivent passer des examens/concours déterminants pour leur vie arrivent à retenir plus de quelques heures.
Mais on peut essayer d’analyser ces formules sans faire de méningite ou déclencher une migraine.
On constate que la VPP et la VPN d’un test dépendent de la prévalence de la maladie.
Plus la prévalence est élevée, plus la VPP est élevée, et plus la VPN est faible.
Plus la prévalence est faible, plus la VPP est faible, et plus la VPN est élevée.
Ca, c’est fondamental à comprendre pour notre pratique quotidienne, presque aussi important que le « primum non nocere » (j’exagère un peu).
Autrement dit, si l’on effectue un test dans une population où la prévalence de la maladie est faible (dans une population à faible risque, pour exprimer les choses autrement) la probabilité qu’un patient avec un test positif soit effectivement malade sera faible, voire très faible. Au contraire, la probabilité qu’un patient soit sain en ayant un test négatif sera très élevée.
Un même test aura donc une performance variable en fonction de la population étudiée.
Si je fais une série d’épreuves d’effort à la recherche d’une coronaropathie aux enfants d’une crèche, un test positif sera peu inquiétant, un test négatif très rassurant.
Si je fais les mêmes épreuves d’effort à la recherche de la même chose dans une population d’hommes dépassant la cinquantaine, hypertendus, tabagiques et diabétiques non traités, un test positif sera très probablement révélateur d’une coronaropathie latente, alors qu’un test négatif sera finalement peu rassurant.
Vous comprenez donc que la performance d’un test est très variable selon le patient à qui on le fait passer. Donc, en corollaire, l’interprétation qu’en fait le médecin doit être adaptée à chaque patient.
C’est difficile à imaginer, mais c’est ainsi: la performance d’un test dépend d’un paramètre qui lui est totalement étranger, la prévalence d’une maladie dans une population.
(moi, cette notion m’a toujours fasciné)
En général, c’est à ce point précis que j’entrevois qu’une bonne partie des examens que l’on me demande, bien que rémunérateurs, sont peu informatifs d’un point de vue statistique.
Prenons l’épreuve d’effort.
Selon cette source, sa sensibilité est environ de 68%, sa spécificité environ de 77%.
Selon cette autre source, la prévalence d’une coronaropathie diagnostiquée à l’angiographie coronaire dans une population générale de 40 à 70 ans est de 7.4%.
Il faut se méfier de jouer à l’apprenti sorcier avec les chiffres, mais cela donne une VPN à 96.79% et une VPP à 19.11%. Ce cas illustre bien le manque de pertinence d’une épreuve d’effort positive dans une population à relativement faible risque.
Dans une population d’insuffisants rénaux à très haut risque, ce papier évalue la prévalence d’une coronaropathie à 53.3%
On obtient alors une VPN à 67.83% et une VPP à 77.14%.
On se rend compte ici que l’épreuve d’effort est ici finalement assez peu pertinente (et encore, je ne tiens pas compte des faibles capacités fonctionnelles musculaires des insuffisants rénaux en stade terminal, diminuant d’autant les performances du test d’effort).
Dans un nombre non négligeable de cas, on se trompe par excès ou défaut.
Vous comprenez donc aussi le paradoxe (apparent) de l'anesthésiste et du cardiologue qui demandent en pré-opératoire un test d'effort pour se rassurer chez un patient à très haut risque cardio-vasculaire. Plus le risque du patient est élevé, et plus la probabilité d'être faussement rassuré par un test négatif est forte. Le "Je l'endors (ou "tu peux l'endormir") tranquille car l'épreuve d'effort est rassurante" prend alors toute sa saveur...
Bien évidemment, en pratique il faut faire une épreuve d'effort avant une chirurgie lourde pour un patient à haut risque. Mais contrairement à ce que l'on croit, c'est plutôt pour sa capacité à dépister une coronaropathie qu'à être "rassuré" avant l'intervention.
Deuxième conséquence de la formule, un peu plus intuitive, celle-çi :
La valeur prédictive d’un test dépend de sa spécificité et de sa sensibilité.
Plus la Sp est élevée, plus la VPP est élevée.
Plus la Se est élevée, plus la VPN est élevée.
Ici, pas trop de soucis, la pertinence d’un test est directement dépendante de ses caractéristiques propres.
Tout cela pour ça, me direz vous…
Cette loi a été décrite par le révèrent Bayes à la fin du XVIIIème, mais sa non compréhension induit au quotidien des demandes statistiquement aberrantes d’examens complémentaires et aussi et surtout des interprétations tout aussi aberrantes que dangereuses pour le patient. Ce ne sont pas tellement les tests qui posent problème, mais plutôt la population dans laquelle ils sont effectués et l'interprétation qu'en fait le médecin demandeur.
Quoique…
Cette note de Jean Daniel Flaysakier évoque un commentaire publié dans le prestigieux magazine Nature sur la fiabilité des tests utilisés pour lutter contre le dopage sportif.
Bien que Donald Berry, l’auteur (un statisticien) a été rétribué par la défense d’un athlète suspecté de dopage en 1996 (merci la déclaration de conflits d’intérêts), son texte apporte un point de vue assez différent de « l’idée commune » qui prévaut sur le sujet.
Faites vous votre opinion.
°0°0°0°0°0°0°0°0°0°0°0°0°
Une fois n’est pas coutume, une petite modification de dernière minute.
Stéphane a aussi évoqué le dopage, mais cette fois en terme d’efficacité dans cette note. Je l’avais lue, mais sur le coup je n’y avais pas pensé. Merci de l’avoir rappelé dans ton commentaire !
12:36 Publié dans Prescrire en conscience | Lien permanent | Commentaires (9)
Commentaires
Le commentaire de nature ne fait que confirmer que le monde du dopage (pardon du sport de haut niveau) et du contrôle antidopage est une immense bouffonnerie.Enormément d'argent est dépensé par les uns pour prendre des substances dont l'efficacité est totalement inconnue sauf pour les stéroïdes et les amphétamines (un édito de science de la semaine dernière sur lequel j'ai posté), et de l'autre coté on cherche tout et n'importe quoi un peu n'importe comment. C'est assez risible. Le sport de haut niveau est un spectacle; il doit respecter les règles du spectacle, show must go on, le reste des atermoiements.
Si vous n'êtes pas convaincu, lisez sur le monde une interview du boss de la NBA.
Sympa la note sur le théorème de Bayes, j'adore ce théorème et ce qu'il implique. Je signale pour ceux qui voudrez comme moi refaire leur gamme en stat, un très bon bouquin, statistics in a nutshell chez O'reilly.
Écrit par : stephane | 10/08/2008
Bravo pour cette introduction car le sujet est glissant.
"C’est difficile à imaginer, mais c’est ainsi: la performance d’un test dépend d’un paramètre qui lui est totalement étranger, la prévalence d’une maladie dans une population."
Hum une façon "simple" de le "voir" est de considérer un test qui ne coûte pas cher car il répond toujours "vous n'êtes pas atteint par la maladie X". Il répond toujours ça, sans rien tester ou en testant ce que vous voulez et je jetant le résultat pour répondre "non".
Ce test ne vaut rien? Hum clairement pourtant si la prévalence est de seulement 1 pour 100 000, le test ne va se tromper qu'une fois sur 100 000. Plutôt fiable comme test :)
Par contre, si 1 patient sur 10 est atteint, le test devient relativement "mauvais".
Les probabilistes diront "bah oui, on ne travaille pas dans le même univers"...mais bon parler de "tribu" et d'"univers" n'aide pas trop à se faire une image intuitive...
Écrit par : xavier | 11/08/2008
Bravo et quel courage de se lancer dans cette démonstration ! De mpn temps, moi le vieux, on n'enseignait pas Bayes en médecine et je l'ai découvert quand je suis parti étudier l'épidémiologie et l'évaluation à Boston.
Au delà de la dimension statistique, je trouve que ce théorème traduit bien la différence entre la pensée anglosaxonne et la nôtre.
Bayes c'est une hypothèse a priori qu'on va accepter de revoir en tenant compte de l'environnement pour aboutir à une valeur a posteriori.
Nous, on nous a nourri à la certitude, pas au doute. Nous sommes le peuple du "risque zéro". Comment faire accepetr qu'un résultat puisse être faussement positif ou négatif dans ces conditions ?
la meilleure preuve c'est la météo : les TV anglaises et américaines donnent les prévisions en pourcentage. nous on entend : " il pleuvra demain". pas 60% de risque de pluie, non "il pleuvra".
C'est peut-être pour cela que Thomas Bayes a pris la place de Laplace.
Juste un mot sur le papier de Berry qui est aussi médecin. J'ai soumis son argumentation à trois sources différentes qui abondent dans son sens. mais là encore, nous sommes dans le dogme. Imaginer qu'un test puisse être discuté est anti-culturel ! Et le plus fort c'est que l'on me rétorque "oui mais avec la répétition du test,on réduit la marge d'erreur". Sauf que c'est tout le contraire.
Écrit par : JD Flaysakier | 11/08/2008
Pardon de revenir en deuxième semaine. Cette fois c'est sur les valeurs d'un test. Il y a une notion essentielle qui a du mal à passer aussi c'est c'elle du "prix à payer". pas seulement la veleur monétaire, mais aussi le coût social, psychologique , éventuellement la iatrogénie, induits par des tests dont on évalue mal les caractéristiques.
Un faux positif qui va entrainer une biopsie ou des biopsies, une angoisse pendant l'attente des résultats, voire d'autres gestes pour finalement infirmer le diagnostic n'est pas tolérable dans toutes les conditions.
On a tendance, ici, à vouer par exemple une vertu magique au mot "dépistage". Mais on ne se pose pas toutes les questions annexes et connexes.
la santé publique nécessite de savoir déplaire, parfois. Mais la culture du risque zéro et l'attitude de certains juges privent nos décideurs de tout courage.
Écrit par : JD Flaysakier | 11/08/2008
Je passe souvent sans commenter, mais là, il le faut ! Revoir les stats élémentaires en cinq minutes, et surtout comprendre, ça ne m'étais jamais arrivé auparavant...
Ma LCA de la semaine prochaine vous remercie !
Écrit par : Stockholm | 16/08/2008
>Stockolm: je te conseille l'achat de ce bouquin: http://grangeblanche.hautetfort.com/archive/2008/02/12/les-statistiques.html
J'ai compris grâce à lui!
Écrit par : lawrence | 18/08/2008
Génial!!!!!! Encore une fois, bravo, c'est clair et concis, j'ai tout compris!
Écrit par : Jeune biologiste post thésarde | 18/08/2008
Bonjour
il me semble qu'il existe une erreur dans la determination des faux positifs
la zone remonte plus haut sur le trait rouge
cordialement
Écrit par : scemama | 09/07/2012
Ah vi, exact!
Merci+++
Écrit par : Lawrence | 09/07/2012
Les commentaires sont fermés.